인공지능
[인공지능] 미국 국립표준기술연구소 NIST, AI 모델 보안성 점검 툴 '디옵트라' 출시 및 개발 지침 발표
오션지키미
2024. 7. 31. 09:44
반응형
미국 국립표준기술연구소(US Department of Commerce’s National Institute of Standards and Technology, NIST)가 어떤 유형의 공격이 AI 모델의 성능을 저하시키는지 확인할 수 있는 오픈소스 소프트웨어 패키지 디옵트라(Dioptra)를 출시하고 안전한 생성형 AI 개발을 위한 가이드라인을 공개했다.

NIST는 성명에서 "ML 모델에 대한 적대적 공격의 영향을 테스트하는 것은 AI 개발자와 고객이 AI 소프트웨어가 다양한 적대적 공격에 얼마나 잘 견딜 수 있는지 판단하는 데 도움을 준다. 이것이 디옵트라의 목표"라고 말했다. 디옵트라는 깃허브에서 무료로 다운로드할 수 있다.
GitHub - usnistgov/dioptra: Test Software for the Characterization of AI Technologies
Test Software for the Characterization of AI Technologies - GitHub - usnistgov/dioptra: Test Software for the Characterization of AI Technologies
github.com
Glossary — Dioptra 1.0.0 documentation
An acronym for the term Jacobian Saliency Map Attack, a type of adversarial machine learning evasion attack that was first proposed in the paper titled “The Limitations of Deep Learning in Adversarial Settings” by Nicolas Papernot, Patrick McDaniel, So
pages.nist.gov
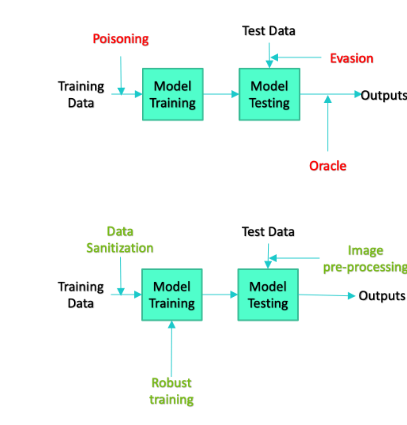
디옵트라는 AI 시스템 개발자가 모델의 성능 저하를 정량화해 시스템이 얼마나 자주, 어떤 상황에서 실패하는지 학습할 수 있도록 지원한다. 2023년 통과된 바이든 대통령의 행정명령에 따라 AI 도구의 안전과 보안을 보장하기 위한 표준 마련의 일환으로 제작됐다.
새로운 소프트웨어 패키지와 함께 NIST는 AI 안전 및 표준을 위한 지침을 담은 문서도 발표했다. 이런 문서에는 '이중 사용 파운데이션 모델의 오용 위험 관리(Managing Misuse Risk for Dual-Use Foundation Models)'라는 파운데이션 모델 개발 지침의 공개 초안이 포함돼 있다. 이 가이드라인은 개인, 공공 안전 및 국가 안보에 고의적으로 해를 끼치는 데 악용되는 것을 방지하기 위해 개발자가 모델을 설계하고 구축하는 과정에서 채택할 수 있는 자발적 관행을 간략하게 설명한다.
초안에서는 모델이 오용될 위험을 완화하기 위한 7가지 접근 방식과 이를 구현하는 방법, 구현 시 투명성을 확보하는 방법을 제안한다. NIST는 "이런 지침을 통해 생물학적 무기 개발, 공격적인 사이버 작전 수행, 아동 성적 학대 자료 및 비합의적이고 사적인 이미지 생성 등의 활동을 통해 모델이 해를 끼치는 것을 방지할 수 있다"라고 말했다. 초안에 대한 의견은 오는 9월 9일까지 수렴한다.
NIST는 파운데이션 모델 개발 지침 외에 개발자가 생성형 AI의 위험을 관리하는 데 도움이 되도록 설계된 'AI 위험 관리 프레임워크(AI Risk Management Framework, AI RMF)'와 '보안 소프트웨어 개발 프레임워크(Secure Software Development Framework, SSDF)'의 보조 역할을 할 2가지 지침을 공개했다.
'AI RMF 생성형 AI 프로필(Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile)'은 생성형 AI의 12가지 잠재적인 위험 목록과 개발자가 이를 관리하기 위해 취할 수 있는 약 200가지 조치를 제안한다. 12가지 위험에는 사이버보안 공격의 진입 장벽이 낮아지는 것, 허위 정보나 혐오 발언 및 기타 유해한 콘텐츠가 생산되는 것, 생성형 AI 시스템이 결과물을 왜곡하거나 환각 현상을 일으키는 것이 포함된다.
두 번째 지침 문서인 '생성형 AI 및 이중 목적 파운데이션 모델을 위한 보안 소프트웨어 개발 관행(Secure Software Development Practices for Generative AI and Dual-Use Foundation Models)'은 SSDF와 함께 사용하도록 설계됐다. NIST에 따르면, SSDF는 소프트웨어 코딩 관행을 광범위하게 다루고 있지만, 이번에 공개된 보조 지침은 AI 시스템의 성능에 악영향을 미치는 악성 학습 데이터로 인해 모델이 손상되는 문제를 해결하기 위해 SSDF를 부분적으로 확장한 것이다.
또한 NIST는 AI 안전을 보장하기 위한 계획의 일환으로 미국 이해관계자가 전 세계 다른 국가와 협력해 AI 표준을 개발할 수 있는 계획을 추가로 제안했다.
2023년 11월, 중국과 미국은 AI의 발전으로 인해 발생하는 모든 위험을 완화하기 위해 최소 25개국과 협력하기로 합의했다. 양국은 EU, 인도, 독일, 프랑스 등 다른 여러 국가와 함께 영국 AI 안전 서밋(UK AI Safety Summit)에서 블레츨리 선언(Bletchley Declaration)이라고 불리는 합의문에 서명하여 AI의 진화를 감독하고 기술이 안전하게 발전할 수 있도록 합의한 바 있다.
728x90
반응형